Apache Tez란 무엇인가?
- IT 정보/Hadoop Eco System
- 2021. 4. 4.
Hive3 버전으로 넘어가면서 기존의 MapReduce 기반의 쿼리 엔진은 공식적으로 권장하지 않게 되었습니다.
Hive3에서 MapReduce를 이용하여 쿼리를 실행시키면 "mapreduce deprecated" 라는 단어를 확인할 수 있습니다.
MapReduce 엔진은 이전부터 워낙에 쿼리 속도 문제에 대한 이슈가 많았기 때문에 이로 인한 조치인 것으로 보입니다.
그리고 이렇게 Hive에서 MapReduce를 대체하기 위해 현재는 Apache Tez를 기본 엔진으로 권장하고 있습니다.
이에 이번 포스팅에서는 Apache Tez는 무엇인지에 대해 먼저 알아보려고 합니다.
Tez VS MapReduce
우선 Apache Tez는 MapReduce와 동일하게 YARN 기반으로 실행되는 데이터 처리를 위한 프레임워크 입니다. 따라서 역시 Tez도 YARN으로부터 컨테이너를 할당받아서 작업을 수행하게 됩니다.
MapReduece는 작업을 처리할때 Map단계에서 데이터를 읽어서 특정 작업을 수행하고, Reduce 단계에서 처리 결과를 저장한 뒤, 중간 작업 결과를 HDFS에 쓰고 다시 Map 단계에서 읽는 등 하나의 작업이 여러개의 MapReduce 과정을 거치게 됩니다.
반면 Tez는 Map단계에서 처리 결과를 메모리에 저장하고, 이를 Reduce 단계로 바로 전달합니다. 그리고 이렇게 결과를 전달받은 Reduce는 Map단계를 다시 거치지 않고 바로 다음 Reduce 단계로 전달하여 IO 오버헤드를 줄여서 속도를 향상을 볼 수 있습니다.
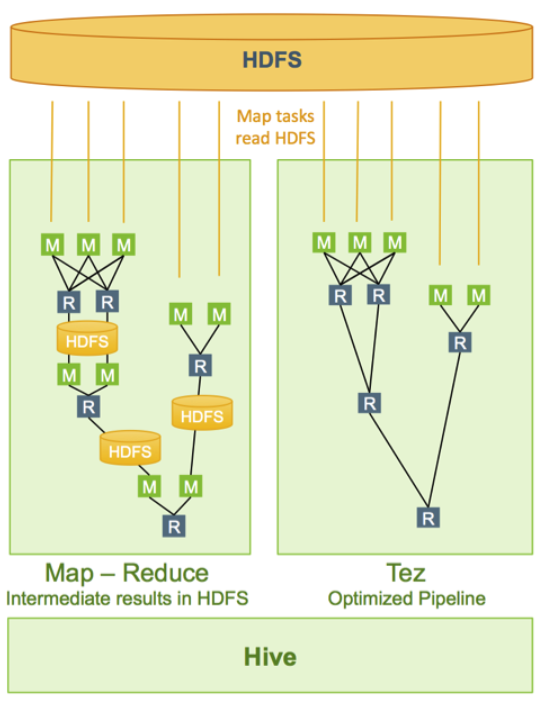
이러한 작업 처리 과정의 차이로 인해 동일 쿼리에서 MapReduce가 50초 가량 걸린 것에 비해 Tez는 20초가 줄어든 30초만에 동일한 쿼리 작업을 처리한 것으로 확인하였습니다.
Tez 실행 엔진 설정
HIVE Config에서 아래와 같이 설정하여 실행 엔진을 Tez로 설정할 수 있습니다.
set hive.execution.engine=tez;
set hive.execution.engine=mr;
set hive.execution.engine=spark;
이번에는 정말 간략하게 Tez에 대해 알아보고 Tez와 MapReduce의 차이에 대해 알아 보았습니다.
다음 포스팅에서는 실제로 Tez를 Hive에 적용하는 상세한 방법에 대해 알아보고, 주의해야할 사항 및 참고해야 할 사항은 없는지에 대해 포스팅할 수 있도록 준비해 보도록하겠습니다.