운영환경에서의 HDFS Erasure Coding
- IT 정보/Hadoop Eco System
- 2019. 7. 12.
*Cloudera Engineering Blog에 기재된 내용 입니다.
출처 : https://blog.cloudera.com/blog/2019/06/hdfs-erasure-coding-in-production/?fbclid=IwAR1agLV-T50SV2MtWyKTDzFIBPoonR-NTR5CWdl7szJ9BAvcaME1QGR80vg
Apache Hadoop 3.0에서 제공되는 주요 기능인 HDFS Erasure coding(EC)는 CDH 6.1.x 이상의 버전에서도 사용할 수 있으며, Spakr 및 MapReduce와 같은 특정 응용 프로그램에서 사용할 수 있습니다.
이전 버전의 HDFS는 여러 데이터 복사본(기존 스토리지 array의 RAID1과 유사)을 복제함으로써 Fault tolerance를 달성하였지만, Hadoop3.0의 HDFS EC는 parity cell(RAID5와 유사)을 사용하여 비슷하거나 더 나은 Fault tolerance를 달성하면서 스토리지의 오버헤드를 크게 줄였습니다.
EC를 도입하기 전에 HDFS는 fault toerance를 위해 replication factor 3(3개의 복제본)을 사용했습니다. 즉, 1GB파일은 3GB의 디스크 공간을 사용합니다. EC를 사용하면 1GB파일도 1.5GB 디스크 공간만 사용하여 동일한 수준의 fault tolerance를 얻을 수 있습니다. 결과적으로 이 기능은 Hadoop을 사용하기 위한 TCO(Total cost of ownership)을 현저히 낮출 것으로 기대합니다.
이 게시물은 최신 성능 결과, EC의 생산 준비성 및 배포 고려 사항에 중점을 둡니다.
용어 설명
- NameNode(NN) : 파일과 블록의 네임스페이스와 메타 데이터를 관리하는 HDFS 마스터 서버.
- DataNode(DN) : 파일 블록을 저장하는 서버.
- Replication : Replication factor 3 (3개의 복제본)을 기본 값으로 하는 HDFS의 기존 복제방식.
- Striped / Striping : HDFS EC에서 도입 된 새로운 스트라이프 블록 레이아웃 양식으로, 기존 복제에서 사용되는 기본 연속 블록 레이아웃을 보완합니다.
- Reed-Solomon(RS) : 기본 EC codec 알고리즘 입니다.
- Erasure coding policy : 이 게시물에서 EC 정책을 설명하기 위해 다음을 사용합니다.
- <codec>-<number of data blocks>-<number of parity blocks>-<cell size>, for example, RS-6-3-1024k
- <codec>(<number of data blocks>, <number of parity blocks>), for example, RS(6, 3)
- Legacu coder : 페이스 북의 HDFS-RAID 프로젝트에서 시작된 legavy Java RS coder.
- ISA-L : SSE, AVX, AVX2, AVX-512와 같은 인텔 명령어 세트에 대한 성능 최적화를 제공하는 RS 알고리즘을 구현하는 인텔 스토리지 가속 라이브러리.
- ISA-L coder : 인텔 ISA-L 라이브러리를 활용하는 기본 RS코더.
- New Java coder : Reed solomon 알고리즘의 순수 자바 구현(필수 CPU 모델이 없는 시스템에 적합). 이 코더는 ISA-L 코더와 호환되며 JVM의 자동 벡터화 기능을 활용합니다.
성능 평가
다음 다이어그램은 Cloudera와 Intel이 두 가지를 제외한 모든 경우에서 EC 성능을 테스트하기 위해 사용하는 하드웨어 및 소프트웨어 설정을 요약 한 것입니다. 장애 복구 및 스파크 테스트는 다음 절에서 설명하는 다른 클러스터 설정에서 실행되었습니다.
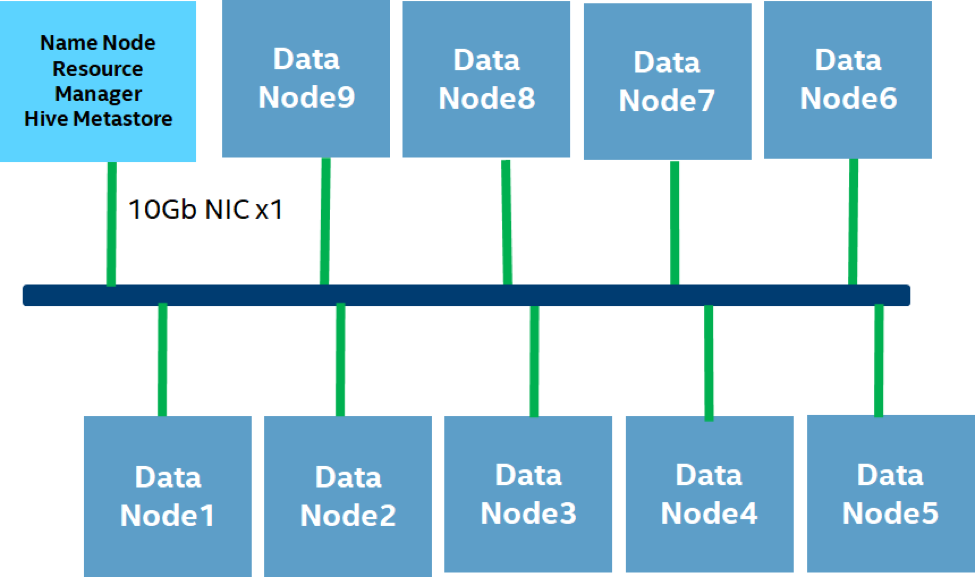
다음 표는 자세한 하드웨어 설정을 보여줍니다. 모든 노드는 동일한 ToR 스위치 아래의 동일한 랙에 있습니다.
| Cluster Configuration | Management and Head Node | Worker Nodes |
| Node | 1x | 9x |
| Processor | 2 * Intel(R) Xeon(R) Gold 6140 CPU @2.30 GHz / 18 cores | |
| Memory | 256G DDR4 2666 MHz | |
| Storage Main | 4 * 1TB 7200r 512 byte/Sector SATA HDD | |
| Network | Intel Corporation 82599ES 10-Gigabit SFI/SFP+ Network Connection | |
| Network Topology | All nodes in the same rack with 10Gbps connectivity | |
| Role | NameNode
Standby NameNode Resource Manager Hive Metastore Server |
DataNode
NodeManager |
| OS Version | CentOS 7.3 | |
| Hadoop | Apache Hadoop trunk on Jun 15, 2018
(commit hash 8762e9c) |
|
| Hive | Apache Hive 2.1.0 | |
| Spark | Apache Spark 2.2.0 | |
| JDK version | 1.8.0_141 | |
| ISA-L version | 2.22 | |
| HDFS EC Policy | RS-6-3-1024k | |
표 1. 자세한 하드웨어 및 소프트웨어 설치
테스트 결과
다음 세션에서는 장애 복구, 사용 가능한 다른 EC코덱의 성능 비교, 복제 및 EC를 다른 성능으로 비교한 IO 성능 테스트 결과를 포함한 EC 및 3x 복제의 성능을 비교하는 TeraSuite 테스트 결과를 살펴보겠습니다. 코덱, TPC-DS 테스트 결과 및 다양한 파일 크기에 대한 EC의 성능 영향을 측정하는 End-to-End Spark 테스트가 포함됩니다.
다음 테스트는 단일 랙 클러스터에서 수행되었습니다. 읽기, 쓰기 및 데이터 재구성이 모두 EC 된 데이터에 대해 원격이기 때문에 EC 성능은 멀티 랙 환경에서 사용될 때 영향을 받을 수 있습니다.
TeraSuite
MapReduce에 포함 된 TeraSuite 테스트 제품군의 TeraGen 및 TeraSort를 사용하여 복제와 EC 간의 End to End 성능 비교에 대한 결과를 얻었습니다.
TeraGen은 쓰기 전용 테스트이며 TeraSort는 읽기 및 쓰기 작업을 모두 사용하는 쓰기 집약 테스트 입니다. TeraSort 는 기본적으로 replication factor가 1인 output 파일을 씁니다.
실험용으로, 우리는 두번의 복제 테스트를 수행했습니다. 하나는 output 파일에 대해 기본 replication factor를 1로 사용하는 것이고 다른 하나는 output 파일의 repolication factor를 3으로 사용하는 것입니다.
각 테스트에 대해 5회 실시되었으며 다음 결과가 평균입니다. TeraSuite 테스트는 1TB 데이터를 사용하도록 설정되었습니다.
다음 표는 작업에 대한 자세한 구성 입니다.
| Configuration Name | Value |
| Number of Mappers | 630 |
| Number of Reducers | 630 |
| yarn.nodemanager.resource.cpu-vcores | 71 |
| yarn.nodemanager.resource.memory-mb | 212 GB |
| yarn.scheduler.maximum-allocation-mb | 212 GB |
| mapreduce.map.cpu.vcores | 1 |
| mapreduce.map.memory.mb | 3 GB |
| mapreduce.reduce.memory.mb | 3 GB |
| mapreduce.map.java.opts | -Xmx2560M |
| mapreduce.reduce.java.opts | -Xmx2560M |
Table 2. Configurations for TeraSort
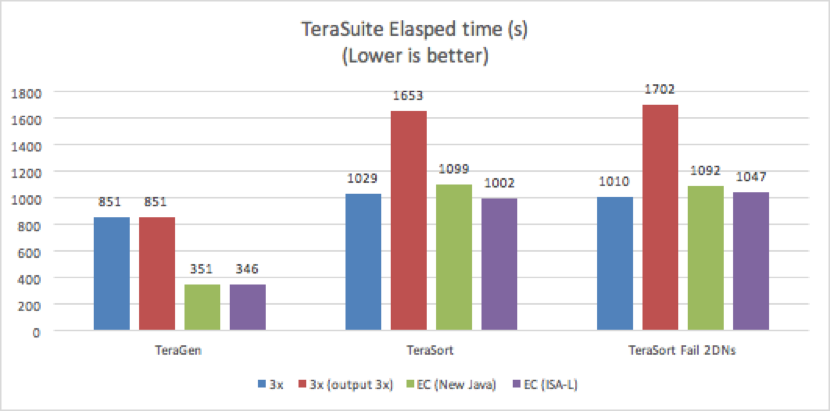
위의 결과는 EC가 TeraGen의 복제보다 50% 이상 빠르게 수행되었음을 나타냅니다. EC는 병렬 쓰기와 상당한 양의 데이터 작성으로 이익을 얻었습니다. EC 쓰기는 replication factor 3가 원래 데이터 크기의 300%를 차지하는데 비해 150%만 차지하면서 동일한 수준의 fault tolerance를 제공합니다.
TeraSort 테스트에 대해서 두개의 다른 실행을 하였습니다. 첫번째 테스트는 모든 DN을 실행하고 두번째 테스트는 TeraSort를 실행하기전 무작위로 선택된 두 개의 DN을 수동으로 종료하였습니다.
실패한 DataNode 테스트에서 TeraSort의 경우 EC는 replication factor 3에 비해 50%이상 빨라졌으며 replication factor 1의 output파일을 사용하여 replication factor 3과 유사한 성능을 달성했습니다.
예상대로 replication factor 3의 복제된 파일이 있는 TeraSort는 1배 복제된 output 파일이 있는 terasort보다 40% 느렸습니다. replication factor 3 테스트는 replication factor 1 output 파일이 있는 테스트보다 3배 더 많은 데이터를 쓰기 때문입니다.
9개의 DataNode 중 2개가 종료된 EC 성능은 9개의 DataNode가 모두 실행된 결과와 유사합니다. 이러한 유사성은 주로 측정 된 종단 간 시간에 저장 시간뿐만 아니라 작업 실행 시간이 포함되기 때문에 발생합니다. 두 개의 DataNode가 종료되었지만 NodeManager가 실행 중이었고 컴퓨팅 성능이 동일했습니다. 따라서 '실시간' 재구성 오버헤드는 계산 오버헤드와 비교할 때 무시할만큼 작습니다.
DFSIO
Replication factor 3 및 EC의 처리량을 비교하기 위해 DFSIO(Hadoop 분산 I/O 벤치마크) 테스트를 실행하였습니다. 테스트에서는 맵퍼마다 25GB의 파일을 처리하는 다양한 수의 맵퍼 테스트가 수행되었습니다. 각 테스트를 실행하기 전에 운영체제 캐시를 정리하였습니다. 결과는 전체 실행 시간으로 측정하였습니다. DFSIO 테스트는 데이터 locality를 사용하지 않으므로, 복제시 데이터 locality의 이점을 누릴 수 있는 운영 사용 사례와 결과가 약간 다를 수 있습니다.
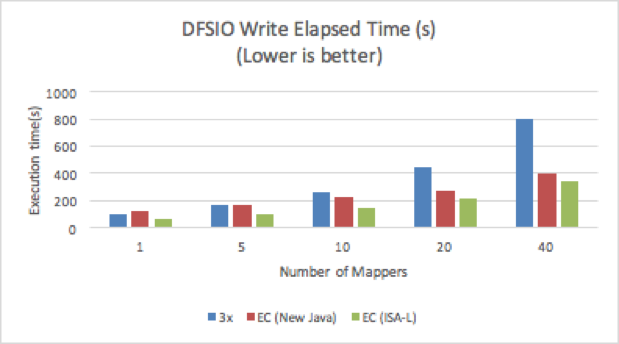
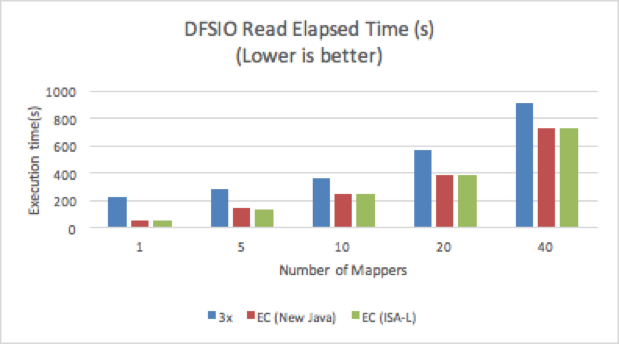
읽기 및 쓰기 테스트에서 ISA-L을 사용하는 EC는 replication factor 3 의 성능 보다 모두 더 나은 성능을 보여주었습니다.
하나의 맵퍼로만 구성된 EC는 읽기 테스트에서 replication factor 3 보다 300% 더 높은 성능을 보여주었습니다. 맵퍼 수가 증가함에 따라 EC는 replication factor 3보다 30% 정도 더 빠릅니다. 맵퍼의 동시성이 높을 수록 Disk I/O 경합이 높아져 전체 처리량이 감소하기 때문입니다. 또한 단일 맵퍼를 사용하는 경우 크로스 클러스터 Disk 활용률이 EC의 경우 이전 replication factor 3 보다 5배이상 높았고, 40개의 맵퍼를 사용하는 경우 Disk 활용률은 동일한 수준이었으며 EC의 성능은 약간만 향상 되었습니다.
쓰기 테스트의 경우, 맵퍼 수가 적을 때 New Java 코덱을 사용하는 EC 보다 replication factor 3의 성능이 더 높지만, ISA-L을 사용하는 EC보다는 30% ~ 50% 느립니다. 40개의 맵퍼를 사용하는 경우 replication factor 3이 가장 느렸으며, EC의 실행 시간보다 2배 이상 소요되었습니다.
TPC-DS
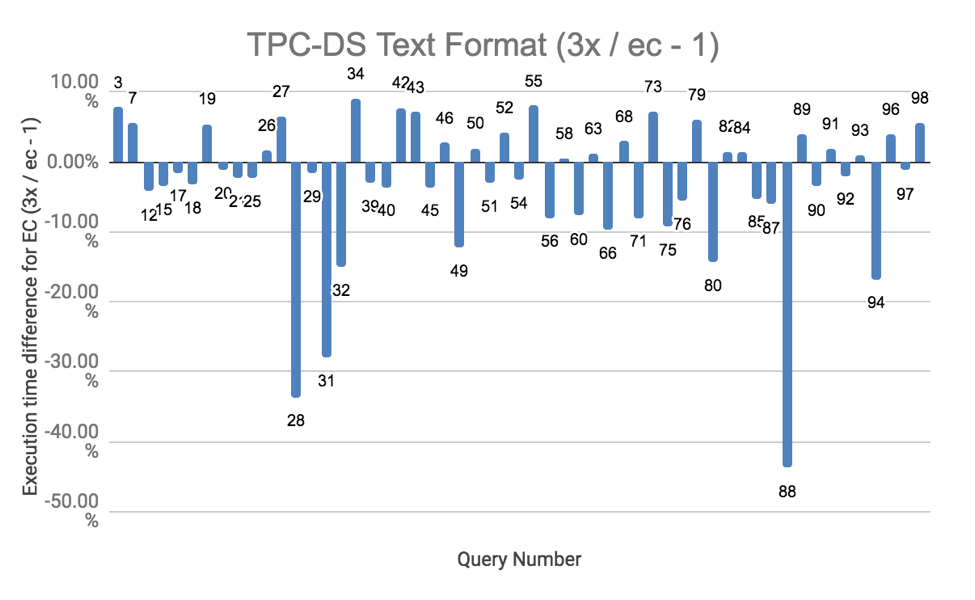
다양한 쿼리의 성능에 대한 결과를 얻기 위해 Hive on Spark를 사용하여 종합적이 TPC-DS 테스트를 실시했습니다. ORC 및 텍스트 형식 모두에 대해 테스트를 실시했습니다. 모든 테스트를 세번 실시했는데, 아래 결과는 평균입니다. 전체 결과는 호기심 많은 독자들을 위해 이 스프레드시트에 나와 있습니다.
TPC-DS 실행 결과에 따르면 EC의 성능이 대부분의 경우 replication 보다 약간 저하되었습니다. 전체 성능 저하에서 중요한 기여 요인은 EC 데이터를 읽고 쓰는 것의 외향성 입니다. EC의 성능이 20% 이상 느린 CPU 집중 쿼리가 몇 개 있었습니다. CPU는 이러한 쿼리를 실행하는데 거의 완전히 사용되었습니다. 패리티 블록 계산으로 인해 EC 데이터에 대해 쓰기가 CPU 집약적이라는 점을 감안하면 실행 시간이 늘어납니다. 이러한 쿼리는 텍스트 형식의 숙자 28, 31 및 88 입니다. 비슷한 이유로, ORC 파일에 사용된 데이터 압축이 전체 CPU 사용량을 증가시켰기 떄문에 ORC 파일 형식을 사용할 때 테스트 결과는 EC에서 약간 더 나빴습니다.